こんにちは。プロダクト開発グループの川口です。自社サービスである FANSHIP のインフラ・運用業務を主に担当しています。
今回は FANSHIP の運用・監視で使用している Datadog の細かい機能について、活用方法や知見などを紹介させていただきます。
なお、記載内容は執筆時点のものであり、情報が古かったり内容が変更されている場合があります。正確な最新情報は Datadog 公式サイトやサポートから入手してください。
Multi Organization
Datadog には複数の Datadog アカウントを同一組織に紐づけて管理することができる Multi Organization 機能があります。
この機能を利用すると、請求の一元化によって無料枠の計算が最適化されるメリットがあります。例えば、アカウントAでは1ホストのみ管理しており、アカウントBでは1ホストと20コンテナを管理している場合、アカウントBでは1ホストあたり10コンテナの無料枠を超えているので、10コンテナ分の追加料金が発生します。最適化されていると、全アカウントの合算となるので、2ホスト20コンテナの計算となり、無料枠内に収まるので追加料金が発生しません。
弊社では元々 Multi Organization 機能を利用せず、複数アカウントを別々に契約していましたが、担当営業の方にご提案頂き、Multi Organization 用のアカウント別途作成して、その管理下に既存アカウントを入れる形で一元管理に移行しました。後から Multi Organization 機能を利用することも可能なので、検討する際は担当営業やサポートに連絡すると良いと思います。
Agent
Datadog Agent (以下 dd-agent ) はホストにインストールするなどして、メトリクスなどを収集するためのソフトウェアです。弊社では、インフラ構成に合わせて dd-agent を導入しています。例えば、EC2 は Datadog 公式の Ansible ロールでセットアップしていて、コンテナ環境ではサイドカーパターンを採用しています。
dd-agent コンテナのヘルスチェック
Datadog の公式 Docker イメージには コンテナヘルスチェック が定義されていて、チェックスクリプト は agent health コマンドの終了コードを利用しています。
簡単なチェックですが、コンテナヘルスチェックがシステム異常の早期発見に役立つ場合があります。実際に弊社で発生した事例として、サービスインしている dd-agent の動作が突然不安定になったことによって、同一インスタンスで稼働しているアプリケーションのパフォーマンスが悪化する事象が発生しました。その際、事象発生の数時間前に dd-agent のコンテナヘルスチェックが unhealthy となっていたことを後日ログから確認しており、それを受けてコンテナヘルスチェックの結果を監視できる仕組みを新たに構築しました。
弊社では大半のシステムで ECS を利用しているのですが、ECS では Dockerfile に記述するだけではコンテナヘルスチェックは有効になりません(厳密にはコンテナホスト内部ではヘルスチェックが行われているが、ECS Agent に連携されない)。ECS上でコンテナヘルスチェック結果を利用するには、タスク定義でコンテナヘルスチェックを改めて定義する必要があります。そうすると、下記の様にヘルスチェック結果をウェブコンソールやAPIから取得することができるようになります。

なお、dd-agent のヘルスチェックは API Key の有効性が確認できないだけで unhealthy となります。タスク定義で基本 (essential) が false のコンテナは問題無いですが、true のコンテナは unhealthy となるとタスク全体が停止するため、サイドカーパターンなどでは思わぬ障害に繋がらないよう注意が必要です。
カスタム Agent チェック
独自のメトリクスを Datadog に連携したい場合の実現方法はいくつかありますが、そのうちの一つに、Python スクリプトを作成して dd-agent のチェックを拡張する方法があります。
サイドカーパターンでデプロイしている dd-agent を拡張することもできますが、弊社では dd-agent 単体のタスクを専用の ECS Fargate クラスター上で稼働させて、カスタムメトリクスをシステム横断的に収集するプラットフォームを構築しています。
このプラットフォーム上に、先述のコンテナヘルスチェックの結果を Datadog にカスタムメトリクスとして連携するスクリプトを稼働させています。その他にも、 mysql インテグレーションや事業ドメインのメトリクスなど、サイドカー dd-agent で稼働させるには適切でないチェックを集約しています。
HTTP チェック
弊社ではサービスの死活監視に dd-agent の HTTP チェックを使用しています。後から登場した Synthetics モニタリングの方がより実ユーザーに近い視点で監視が行えるので、機能的には優れているのですが、コストの問題で Synthetics は一部導入に留まっています。ただ、HTTP チェックは dd-agent をセルフホスティングする分、構成の柔軟性があるため、コストパフォーマンスに優れた方法として選択肢に充分入ると思います。
Dashboards
Dashboard はメトリクス等をグラフィカルにまとめて表示するページを自由に作成できる機能です。弊社では主に「サービスレベル」と「システムリソース」を Dashboard にまとめており、どちらも週次の運用定例会で目視による確認に使用しています。サービスレベルの Dashboard はコロナ禍によるリモートワークになる前は、社内の大型モニターに常時表示していました。時間経過で人的対応が必要になることが明確なキャパシティ等については Monitor を設定していますが、長期間の傾向変化による異常検知などは目視による定期的な確認で補っています。
サービスレベルは右上のタイムフレームで指定した期間中の値と、日別のサービスレベルを一か月分表示するウィジェットを配置しています。また、サービスレベル目標の定義も同じ Dashboard 上のメモに記載して一元定義しています。

システムリソースは template variables を利用してできるだけ一つの Dashboard で複数のインフラリソースを確認できるようにしています。また、week before を使用して一週間前のメトリクスも同じグラフ領域に表示するようにしています。タイムフレームは通常1週間で確認していますが、月初は長期的な傾向を確認するため6か月の期間で確認しています。

Monitors
Datadog を利用していて Monitor 機能を使用していない方は居ないと思いますが、弊社で工夫している点として、Monitor 設定は監視対象のリソースごとではなくメトリクスごとに作成し、Multi Alert 機能でリソースごとに監視を行えるようにしています。もちろん共通の閾値が用いれる場合に限られますが、新しいリソースが増えても自動的に監視対象に追加されるため、監視漏れリスクや作業コストの増加を防げます。

Integrations
Datadog の Integrations はウェブ上でポチポチするだけで気軽に利用できるものが多いのですが、想定していない費用が発生している可能性があります。例えば、AWS系 Integrations は有効化することによって、基本的に CloudWatch API への定期アクセスが発生するため、GMD-Metrics などの AWS の料金が増加します。気づかぬうちにまあまあな金額に達していることがあるので、不要な Integrations は無効化するようにしましょう。
また、API key や Application Key について、管理のベストプラクティスは正直なところ分かっていないのですが、API Key はデフォルトでアカウントにつき最大5つしか作成できないので、よく考えて発行する必要があります。
Logs
Logs 機能については、以前 Japan Datadog User Group Meetup#1 で発表させて頂いたスライドがあるので、そちらを転載させていだきます。
Synthetics
弊社では一部しか導入していない Synthetics ですが、SSL証明書の有効期限監視にも使用しています。FANSHIP で使用している SSL 証明書は ACM で自動更新しているため、期限切れ状態に陥る可能性は低いのですが、万が一の際の影響を考えて念のため監視を行っています。
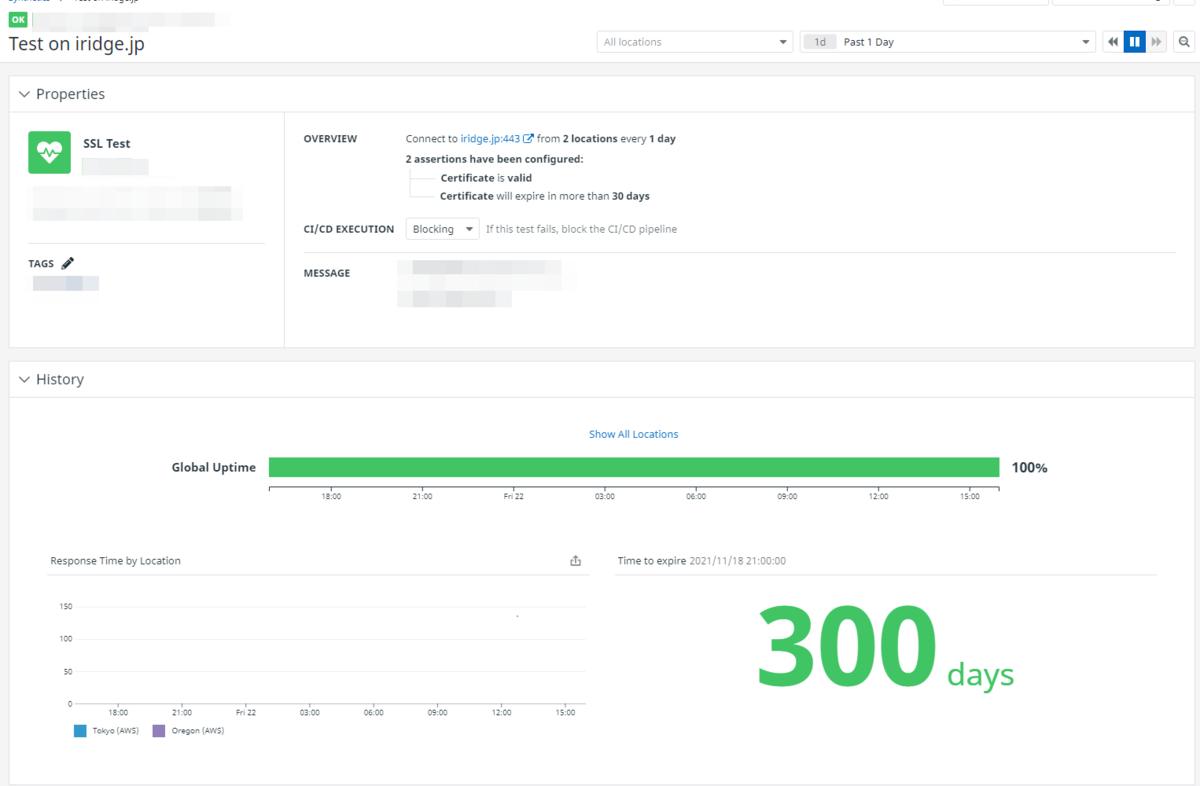
また、外形監視の設定については、最近弊社メンバーが記事を作成してくれたので、よろしければそちらもご覧ください。
最後に
Datadog に関しては、他にも弊社メンバーが記事を作成していますので、ご興味がありましたら是非ご確認ください。また、今後も Datadog 関連の記事が掲載されると思いますので、定期的に本ブログをチェックいただけましたら幸いです。