こんにちは。プロダクト開発グループの中野です。
先日、Pythonの標準モジュールを使用したリトライ付き並列処理でAirflowのTASK分割による並列処理を置き換え、大幅な性能向上とコストダウンを実現しました。平易な内容ではありますが、誰かのお役に立てばと思い紹介させていただきます。
目次
- 課題
- 実装
- 要件
- 実装
- 結果
- 今後の展望
課題
弊社では一部の定時バッチ処理環境にCloud Composer 1を使用しています。Cloud ComposerはGCPのAirflowマネージドサービスです。 弊社のバッチ処理の一部に、約1万件の集計クエリをBigQueryに発行する処理があります。各クエリは負荷が小さいことから、AirflowのBigQueryOperatorを使用し、TASKを並列化することで複数のクエリを同時実行して処理時間の短縮を図っていました。
並列化による処理時間短縮は実現できていましたが、安定性とコストには課題を抱えていました。AirflowのノードはBigQueryを呼び出すだけで実データ処理は行わないにも関わらず、Airflow TASKの起動・終了にCPUとメモリを大量に消費し、負荷に耐えられずに処理が失敗することがありました。安定性を確保するためにリソースを多めに割り当てる必要があり、高コスト体質でした。
下記のグラフは処理中のscheduler, worker nodeの負荷、CPU使用率の単位はCPU個です。8vCPUのVMを8ノード割り当てており、最も負荷の高いノードはCPUを使い切っています。
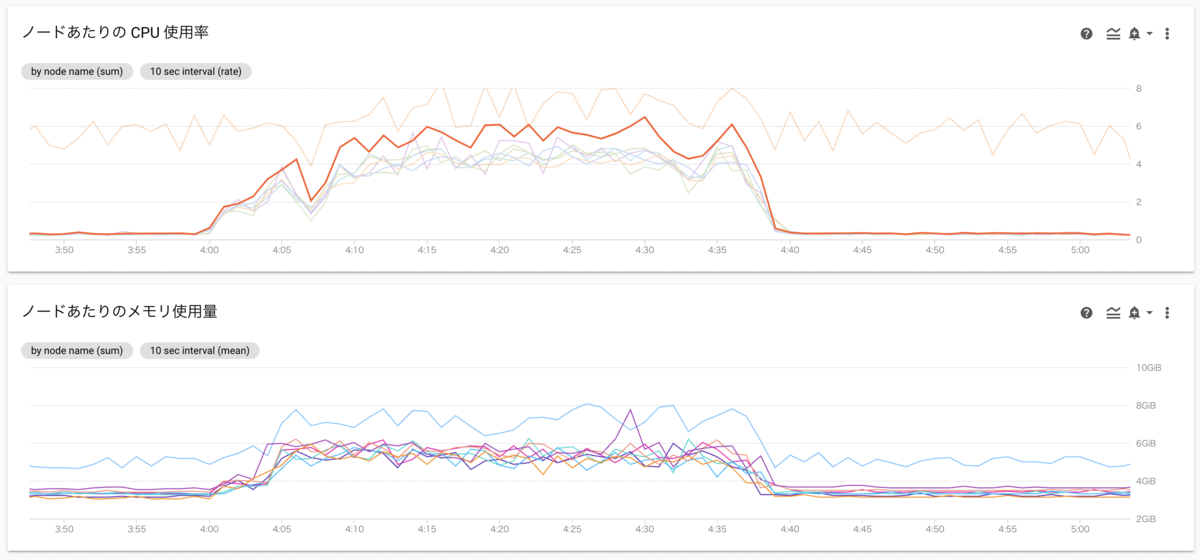
Composerのメジャーバージョンを2系に変更すれば状況はかなり改善されることは確認できていましたが、「Airflow自身は処理をしないのにリソースを多く消費する」という傾向自体は残っていました。そのため、Composerのバージョンアップに加えてBigQueryOperatorのTASKを並列化することを止め、Pythonのマルチスレッド処理でクエリを並列実行することにしました。
実装
要件
並列処理の実装にあたり、Airflowが実現してくれていた機能の一部を自分で実現する必要があります。
- 複数のクエリを同時に実行できること
- 失敗したクエリを一定時間後に再実行できること
- BigQuery, ネットワークの一時的な不調やクエリの実装ミス等でクエリ実行が失敗することがあります。一定の時間をおいて再実行を試みたいのですが、待機中には他のクエリの実行を進めることが期待されます。
- 失敗した処理の特定
- Airflowの場合、エラー・タイムアウトで処理が失敗した場合は該当TASKを簡単に特定でき、リカバリに進むことができます。自分で並列処理を実装する場合も、失敗した処理と原因の特定、リカバリが簡単に行える必要があります。
- 可読性
- 実装が複雑になったりコード量が増えることは避けなければいけません。
実装
並列処理の実装にはconcurrent.futuresを使用しました。 concurrent.futuresを使用すると簡潔に並列処理を実装できます。ただ、処理の一部が失敗した場合に、何をどんな引数で実行して失敗したかを特定・再実行する手段が用意されていないため、失敗した処理対象を収集・再実行する実装を追加してラッパーを作成しました。
class ThreadingExecutor: def __init__(self, max_workers: int=16, max_try: int=1, retry_interval: int=60): """ 並列度を受け取り、スレッドプールを作成する """ self.executor = ThreadPoolExecutor(max_workers=max_workers) self.max_try = max_try # 最大試行回数 self.retry_interval = retry_interval # リトライ間隔 self.tasks = {} self.wait_for_worker_threads = True def submit(self, callable: callable, *args, **kwargs): """ スレッドプールで処理するcallableと引数をキューに追加する """ task = self.executor.submit(callable, *args, **kwargs) # どんなcallableをどんな引数で呼び出したか辞書に記録しておく self.tasks[task] = {'callable': callable, 'args': args, 'kwargs': kwargs} def wait(self, timeout=3600) -> (list, list): """ 処理完了を最大timeout秒間待ち、(処理が正常終了したタスクのリスト, 処理が失敗したタスクのリスト) を返却する。 各タスクは {'callable': callable, 'args': args, 'kwargs': kwargs, 'result': 処理結果} の形式で返却される。 処理結果は、正常終了した場合は関数の返り値、失敗した場合は{'error': エラーオブジェクト, 'stacktrace': スタックトレース文字列} """ success = [] remaining = timeout # タイムアウトまでの残り時間 for n_try in range(1, self.max_try + 1): t0 = time() completed, uncompleted = wait(self.tasks.keys(), timeout=remaining, return_when=ALL_COMPLETED) failure = [] # 完了したタスクの結果を収集 for task in completed: v = self.tasks[task] try: v['result'] = task.result() success.append(v) except Exception as e: v['result'] = {'error': e, 'stacktrace': traceback.format_exc()} failure.append(v) # 未完了のタスクはタイムアウトで失敗とする # 未完了のタスクが存在することは処理全体のタイムアウトを意味するため、最大試行回数に未達でも再実行はせず処理完了とする if uncompleted: for task in uncompleted: v = self.tasks[task] v['result'] = {'error': TimeoutError('timeout'), 'stacktrace': 'worker timed out'} failure.append(v) # タイムアウト発生時はworker threadの正常終了を待つといつまでも終了できない可能性があるため、強制終了する self.wait_for_worker_threads = False break # 全タスクが完了している時、全タスクが成功しているか最終試行であれば処理完了とする if not failure or n_try == self.max_try: break # 失敗したタスクだけ再実行する # 基本的にはretry_interval秒待機してから再実行するが、待機するとタイムアウトする場合は待たずに即実行する elapsed = time() - t0 if elapsed + self.retry_interval < remaining: sleep(self.retry_interval) remaining -= (elapsed + self.retry_interval) else: remaining -= elapsed self.tasks = {} for v in failure: logging.warning(f'Retry callable={v["callable"]}, args={v["args"]}, kwargs={v["kwargs"]} because of {str(v["result"]["error"])}') self.submit(v['callable'], *v['args'], **v['kwargs']) return success, failure def __enter__(self): return self def __exit__(self, exc_type, exc_val, exc_tb): self.executor.shutdown(wait=self.wait_for_worker_threads) return False
記述が長くて恐縮ですが、ポイントは Executorにsubmitして受け取ったFutureオブジェクトを、submitしたcallable・引数と紐付けて保存しておくこと です。
実際に利用してみます。
from parallelism import ThreadingExecutor def dummy_task(a: int, b: int) -> float: return a / b data_to_process = [ (1, 2), (2, 4), (1, 0) # エラーが発生する ] with ThreadingExecutor(max_workers=5, max_try=2, retry_interval=1) as executor: for args in data_to_process: executor.submit(dummy_task, *args) succeeded, failed = executor.wait(timeout=4) # 正常終了したタスクの情報 for task in succeeded: func_name = task['callable'].__name__ args = task['args'] result = task['result'] print(f'{func_name}(*{args})) は成功しました。結果: {result}') # エラー終了またはタイムアウトしたタスクの情報 # 実際の処理では、ここでリカバリ用の設定をログに書き出す for task in failed: func_name = task['callable'].__name__ args = task['args'] error = task['result']['error'] print(f'{func_name}(*{args})) は失敗しました。原因: {error}')
実行結果
$ python3 example.py
WARNING:root:Retry callable=<function dummy_task at 0x104627280>, args=(1, 0), kwargs={} because of division by zero
dummy_task(*(2, 4))) は成功しました。結果: 0.5
dummy_task(*(1, 2))) は成功しました。結果: 0.5
dummy_task(*(1, 0))) は失敗しました。原因: division by zero
concurrent.futures.ThreadPoolExecutor に近い簡潔な実装で、失敗したタスクのリトライ、各タスクの成否の管理が行えていることが分かります。
実はこの実装には大きな問題があります。エラー終了するタスクとwait()がタイムアウトするタスクが混在した場合、エラー終了するタスクの再実行が行われません。今回の用途はBigQueryのクエリ実行並列化で、クエリタイムアウトをExecutorのタイムアウトよりも短くすることで問題なく利用できているのですが、他の用途で利用する際には修正の必要があるでしょう。
結果
Airflow TASKのオーバヘッドがなくなったため、少ないリソースで安定して動作するようになりました。 並列処理を内製した分のコードは増えてしまうのですが、全体的に実装を改善した結果、全体としてはコードの量と複雑度も抑えることができました。
| BigQueryOperatorによる並列化(元実装) | Threadpoolによる並列化(新実装) | |
|---|---|---|
| 割当CPU数 | 64 (8 * 8node) | 3 (worker:2, scheduler:1) |
| 割当メモリ | 128GB (16GB * 8node) | 6GB (worker: 4GB, scheduler: 2GB) |
| コスト | 約 $2,400/月 | 約 $400/月 |
| 実行時間 | 約40分 | 約20分 |
| コード行数 | 2224 | 1257 |
| Cognitive Complexity | 161 | 140 |
処理中のworker, schedulerの負荷は大きく下がりました。


今後の展望
今回の改修で並列化とリトライにAirflowの機能を利用するのを止めました。複雑なワークフローを組んでいるわけではないので、Composerを使い続ける理由は弱くなっています。Cloud RunやBatchなど、必要なときだけリソースを確保するタイプの基盤に移設して、更にコストダウンを図りたいです。 また、エラー終了とタイムアウトが混在した場合にリトライが行われない問題を解決し、BigQuery呼び出し以外の用途でも利用できるように改善したいと考えています。
おわりに
今回は、リトライ付きの並列処理をPythonで実装する方法と利用例をご紹介しました。平易な内容でしたが、お役に立つことがあれば幸いです。
本件に限らず弊社ではPythonを多くの箇所で利用しており、PyConJPにもスポンサーとして協賛しています。今年のPyConJPにはブース出展を予定しておりますので、ぜひお立ち寄りください! 私も担当者としてブースに立つ予定です。